This paper was authored by Sarah Shoilee (Vrije Universiteit Amsterdam), Annastiina Ahola (Aalto University), Heikki Rantala (Aalto University), Eero Hyvönen (Aalto University), Victor de Boer (Vrije Universiteit Amsterdam), Jacco van Ossenbruggen (Vrije Universiteit Amsterdam), and Susan Legene (Vrije Universiteit Amsterdam). It reflects a fruitful collaboration between VU Amsterdam and Aalto University in Finland, made possible through Sarah’s research visit to Aalto in early 2025.
In this work, we explored how Linked Data and semantic exploration tools can be applied to support knowledge discovery in the domain of provenance research for colonial heritage collections. Using the PM-Sampo platform, we developed methods to visualize and extract provenance-related knowledge—such as the people, places, and historical events connected to cultural heritage objects—helping researchers uncover patterns that are often buried in complex archival data.
We are honored that the SemDH reviewers and community recognized the contribution of our work. We believe this award not only reflects the strength of our interdisciplinary collaboration but also the growing importance of semantic infrastructure in the Digital Humanities.
A big thank you to the SemDH organizers, reviewers, and the vibrant community around it. And heartfelt thanks to all our co-authors—it’s been a pleasure to work together!
We look forward to continuing this research and welcome new conversations and collaborations.
Authors: Sebastiaan Berendsen and Emma Beauxis-Aussalet
AI systems are vulnerable for biases that can lead to unfair and harmful outcomes. Methods to detect such biases in AI systems rely on sensitive data. However, this reliance on sensitive data is problematic due to ethical and legal concerns. Sensitive data is essential for the development and validation of bias detection methods, even when using less privacy-intrusive alternatives. Without real-world sensitive data, research on fairness and bias detection methods only concern abstract and hypothetical cases. To test their applicability in practice, it is crucial to access real-world data that includes sensitive data. Industry practitioners and policymakers are crucial actors in this process. As a society, we need legal and secure ways to use real-world sensitive data for bias detection research.
In this blog, we discuss what bias detection and sensitive data are, and why sensitive data is required. We also outline alternative approaches that would be less privacy-intrusive. We conclude with ways forward that all require collaboration between researchers and industry practitioners.
What is bias detection?
AI fairness is about enabling AI systems that are free of biases. A key approach to analyze AI fairness is bias detection. Bias detection attempts to identify structural differences in the results of an AI system for different groups of people. Most methods to detect bias use sensitive data. Sensitive data describes the characteristics of specific socio-demographic groups1. These characteristics can be inherent (e.g., gender, ethnicity, age) or acquired (e.g., religion, political orientation), and are often protected by anti-discrimination laws and privacy regulations. If sensitive information is not used in an AI system, its outcomes can still be biased. We therefore need to explore how we can use sensitive data legally and ethically for bias detection.
In practice, sensitive data is often completely unavailable or of poor quality due to privacy, legal, and ethical concerns. The lack of access to high-quality sensitive data hinders the implementation of bias detection methods in practice.
Concerns regarding the use of sensitive data
The use of certain sensitive data for bias detection might be prohibited by the GDPR2. However, the EU AI Act provides an exception to the GDPR that allows the use of special category data for bias detection purposes. Such usage of sensitive data is subjected to appropriate safeguards. Yet, the definition of appropriate safeguards remains unclear and the exception is strictly limited to the high-risk models defined by the EU AI Act.
Even if the EU AI Act might address some legal concerns, key ethical concerns remain3,4. Widespread collection of sensitive data increases the risks of data misuse and abuse, such as citizen surveillance. Furthermore, obtaining accurate, representative sensitive data is a challenge. Inaccurate sensitive data harms the validity of bias detection methods and heightens the risk of misclassifying and misrepresenting individuals and their social groups.
Alternative approaches
Two approaches5 seem most promising to enable bias detection w.r.t. sensitive data: the trusted third party approach and the analytical approach. The trusted third party approach consists of letting a neutral party hold sensitive data, and run bias analyses on their premises. Such third parties do not share any sensitive data, but only the results of the bias analysis. These trusted third parties can be governmental organizations, such as national statistics or census bureaus, or non-governmental organizations.
The analytical approach consists of data analysis methods that do not require direct access to sensitive data. For example, such methods can be based on proxy variables, unsupervised learning models, causal fairness methods, or synthetic data generated with privacy-preserving technologies. Some of these methods could still require some sensitive data, but they remain less privacy-intrusive than other methods.
These alternative approaches do not structurally remove the need to use sensitive data. Besides, these approaches are currently understudied, and more research is needed to develop and validate them. This research requires controlled access to sensitive data, until such privacy-preserving bias detection approaches are properly validated, and their strengths and weaknesses are well-defined and measurable.
Ways forward
The lack of access to realistic data from real-world AI systems is a crucial challenge. The literature on AI fairness mostly relies on datasets with limited practical context1. Therefore, existing bias detection methods are primarily tested “in-the-lab”. Insights into the validity of the bias detection methods in real-world applications are lacking. Yet, such insights are essential to justify the needs for collecting sensitive data to address AI bias in practice. This is required to understand whether the methods to address AI fairness are effective or not in the socio-technical context of AI systems.
Researchers cannot fix this challenge on their own. Collaboration between researchers, (non) governmental organizations, and industry practitioners is essential to address the challenges with fairness methods, and to increase their practicality and validity. A research collaboration is also needed to address the legal and ethical concerns, and specify the necessary safeguards. For example, the GDPR and EU AI Act contains exceptions for sensitive data processing for scientific purposes, when it adheres to recognised ethical standards for scientific research.
Closing
Sensitive data is essential for investigating the technical approaches to ensure AI fairness. However, the availability of accurate sensitive data remains a challenge. Alternative approaches exist to preserve privacy while using sensitive data for bias analysis. Yet these approaches are currently understudied, and more research is needed. For such research to be effective, collaboration is needed between researchers and practitioners from industry or public institutions.
Together with Angelica Maineri, UCDS’ own Shuai Wang wrote an article on the ODISSEI website on FAIR Implementation profiles in the Social Sciences. A FAIR Implementation Profile (FIP) is a collection of resources, services, and technologies adopted by a community to implement the FAIR principles. In their article “FAIR yes, but how? FAIR Implementation Profiles in the Social Sciences” Shuai and Angelica describe what FIPs are, why they should be used, and how a FIP can be initiated.
Last week, the renowned French philosopher, sociologist, and anthropologist Bruno Latour passed away at age 75 (1947-2022). Latour is considered to be one of the most influential thinkers of modern-day science. His Actor-Network theory (ANT) and mediation theory are known to provide an alternative perspective to the famous subject-object dichotomy, a dominant paradigm in science originating from Kant.
In view of the current critical ethical issues with AI systems pervading our societies, reviewing Latour’s ANT provides invaluable insights into the human network that can create or mitigate the threats of AI.
Read more about it in the blog Mirthe Dankloff (PhD Candidate) wrote for the Civic AI Lab
We are very proud to announce that this January, the Civic AI Lab [1] was awarded to be part of the UNESCO’s TOP 100 International List of Artificial Intelligence (henceforth: AI) solutions for sustainable development for the benefit of humanity [2].
The TOP 100 was created by the International Research Centre on AI (UNESCO) to celebrate the development of AI-based solutions around the world related to the 17 United Nations Sustainable Development Goals [2]. The Civic AI Lab was granted in the category ‘early-stage project’ as the reviewers see great potential in the research lab which just had its one-year anniversary.
The Civic AI Lab is a research collaboration between the City of Amsterdam, The Dutch Ministry of Interior Affairs, the Vrije Universiteit Amsterdam (VU), and the University of Amsterdam (UvA). The Lab’s mission is to support an engaging society where all citizens have equal opportunity to participate and benefit from AI in a fair and transparent manner.
In this capacity, the Civic AI Lab focuses on the application of AI while respecting human rights such as privacy, non-discrimination, and equal opportunity in five domain-specific projects: education, health, welfare, mobility, and environment as well as, two domain-overarching projects: on the intersection of AI and Law, and on the intersection of AI and Public Governance.
Three of our researchers at UCDS are currently affiliated with the Civic AI Lab. Being part of UNESCO’s TOP 100 alongside projects from all continents is a true acknowledgment of the Lab’s work.
We currently disseminate, share, and evaluate scientific findings following paradigms of publishing where the only difference from the methods of more than 300 years ago is the medium in which we publish – we have moved from printed articles to digital format, but still use almost the same natural language narrative with long coarse-grained text with complicated structures. These are optimized for human readers and not for automated means of organization and access. Additionally, peer reviewing is the main method of quality assessment, but these peer reviews are rarely published and have their own complicated structure, with no accessible links to the respective articles. With the increasing number of articles being published, it is difficult for researchers to stay up to date in their specific fields, unless we find a way to involve machines as well in this whole process. So, how can we make use of the current technologies to change these old paradigms of publishing and make the process more transparent and machine-interpretable?
In order to address these problems and to better align scientific publishing with the principles of the Web and linked data, my research proposes an approach to use nanopublications – in the form of a fine-grained unifying model – to represent in a semantic way the elements of publications, their assessments, as well as the involved processes, actors, and provenance in general. This research is a result of the collaboration between Vrije Universiteit Amsterdam, IOS Press, and the Netherlands Institute for Sound and Vision for the Linkflows project. The purpose of this project is to make scientific contributions on the Web, e.g. articles, reviews, blog posts, multimedia objects, datasets, individual data entries, annotations, discussions, etc., better valorized and efficiently assessed in a way that allows for their automated interlinking, quality evaluation, and inclusion in scientific workflows. My involvement in the Linkflows project is in collaboration with Tobias Kuhn, Davide Ceolin, Jacco van Ossenbruggen, Stephanie Delbecque, Maarten Fröhlich, and Johan Oomen.
Semantic publishing
One concept that first comes to mind and a proposed solution to make scientific publishing machine-interpretable is “semantic publishing.” This is not a new concept, as its roots are tightly coupled to the notion of the Web, with Tim Berners-Lee mentioning that the semantic web “will likely profoundly change the very nature of how scientific knowledge is produced and shared, in ways that we can now barely imagine” [1]. Despite the fact that semantic publishing is not directly linked to the Web, its progress was highly influenced by the rise of the “semantic web.” As such, in the beginning, it referred to mainly publishing information on the Web in the form of documents that additionally contain structured annotations, so extra information that is parsable by machines in the form of semantic markup (with markup languages like RDFa, for example). This allowed published information on the Web to be machine-interpretable, to the limited extent to which the markup languages allowed. A next step was to use semantic web languages like RDF and OWL to publish information in the form of data objects, together with a specific detailed representation called ontology that is able to represent the domain of the data in a formal (thus machine-interpretable) way. The information published in such structured ways provides not only a “semantic” context through the metadata that describes the information, but also a way for machines to understand the structure and even the meaning of the published information [2,3].
In this way, semantic publishing would allow for the “automated discovery, enables its linking to semantically related articles, provides access to data within the article in actionable form, or facilitates integration of data between papers” [3]. However, despite all the advancements in the semantic web technologies in the past years, semantic publishing is not “genuine” [4] in the sense that the current scientific publishing paradigm has not changed much as we are still using long articles written in natural language that do not contain formal semantics from the start that machines can process and interpret in an automated manner. So, with scientific publishing often stuck to formats optimized for print such as PDF, we are not using the advances that are available to us with technologies around the semantic web and linked data.
Transforming scholarly articles into small, interlinked snippets of data
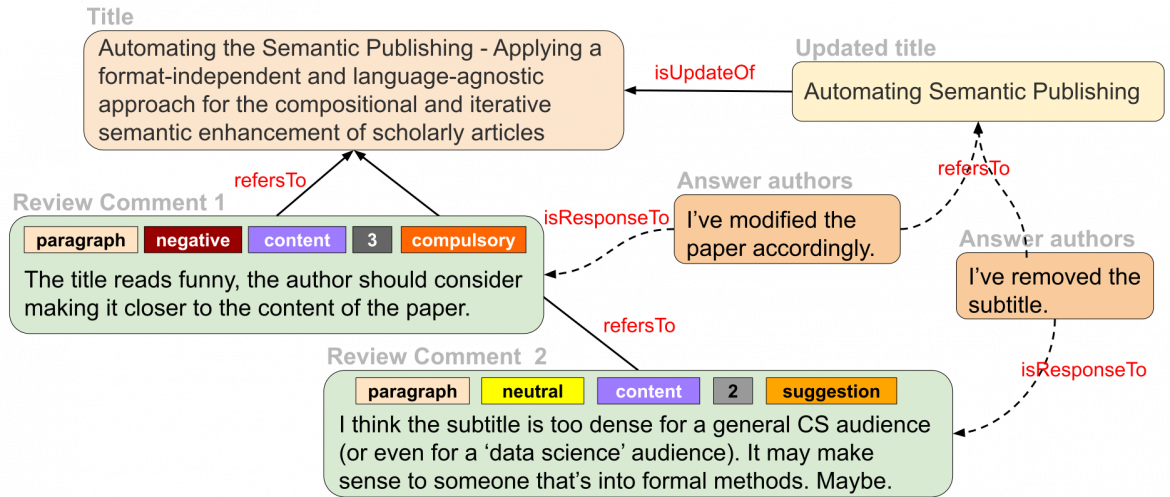
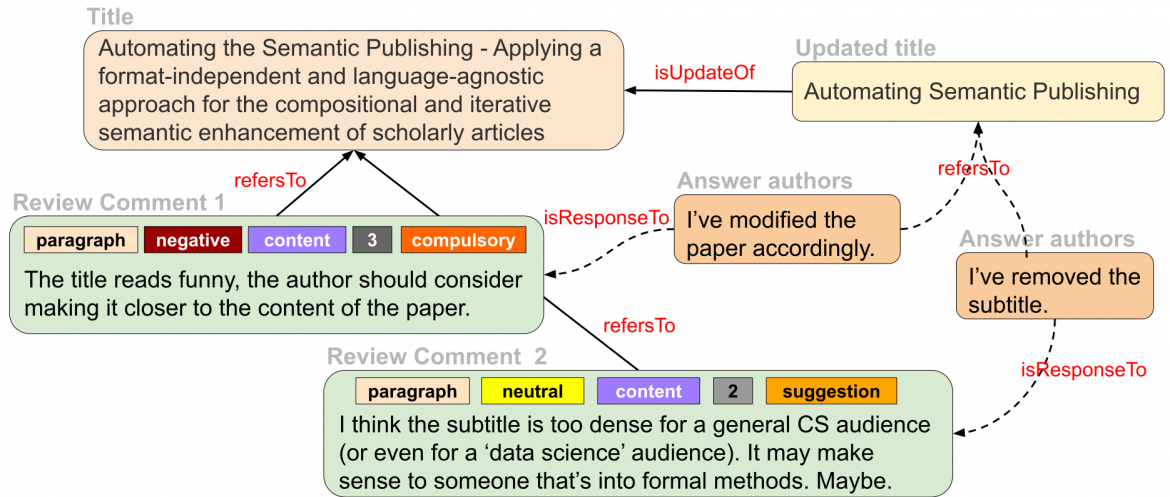
In our approach, we argue for a new system of scientific publishing that contains smaller, fine-grained, formal – machine-interpretable – representations of scientific knowledge that are linked together in a big knowledge network in a web-like fashion in a way that these publications do not need to be necessarily linked to a journal or a traditional publication and can be publication entities by themselves [5,6]. Moreover, semantic technologies make possible the decomposition of traditional science articles into constituent machine-readable parts that are linked not only with one another, but also to other related fine-grained parts of knowledge on the Web following the linked data principles. So, we designed a model for a more granular and semantic publishing paradigm, which can be used for scientific articles as well as reviews.
Figure 1: The scientific publishing process at a granular level:
The scientific publishing process at a granular level
An example based on this is shown in Figure 1. Here, we see how the scientific publishing process can look at a more finely-grained level, with a network-like representation and with the recording of formal semantics for the different elements. Instead of treating big bulks of text as such, we propose to represent them as small snippets – such as paragraphs, or a title in this example – that have formal semantics attached and can be treated as independent publication units. They can link to other such units and therefore form a larger entity – such as a full paper or review – by forming a complex network of links. With that approach, we can ensure that provenance of each snippet of information can be accurately tracked together with its creation time and author, and therefore allow for more flexible and more efficient publishing than the current paradigm.
Reimagining the peer-review process
A process like peer reviewing can then be broken down into small snippets and thereby take the specialization of reviewers and the detailed context of their review comments into account, and these review comments can formally and precisely link to exactly the parts of the paper they address. These small snippets of text can be represented as nodes in a network and can be linked with one another with semantically-annotated connections, thus forming distributed and semantically annotated networks of contributions.
The individual review comments are semantically modeled with respect to the specific part of the paper that they target – whether they are about syntax or content, whether they raise a positive or negative point, and whether they are a suggestion or compulsory, and what their impact on the quality of the paper is, according to our previous proposed model [7]. Each article, paragraph, and review comment thereby forms a single node in a network and is each identified by a dereferenceable URI (uniform resource identifier). All this is very different to how scientific communication happens nowadays, with the long non-machine interpretable natural-language coarse-grained texts, thus large non-semantic documents.
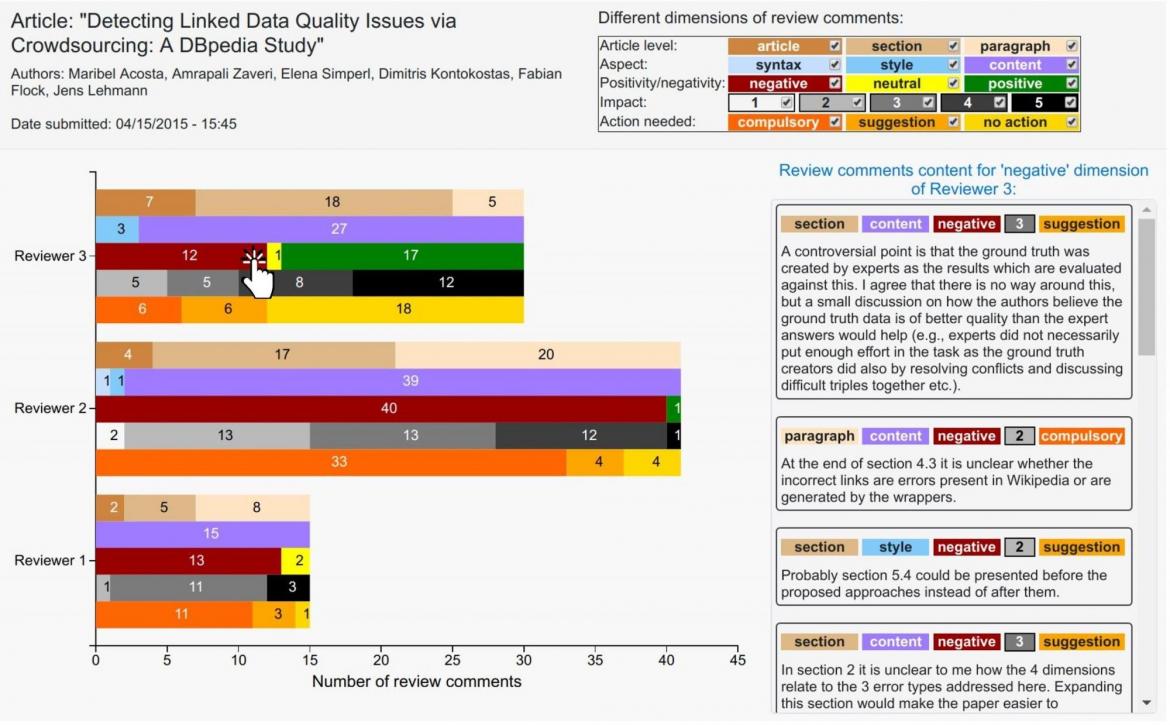
Practical applications for journal editors
This formal networked approach allows us, among other things, to provide general, user-friendly, and powerful aggregations, for example for journal editors, that can assist them in their meta-reviewing tasks. Shown in Figure 2 are two screenshots from a prototype system [8]. We can see in a more quantitative way the set of review comments and their types represented in different colors, where the checkboxes in the legend can be used to filter the review comments of the given category. To see the content of the review comments that are in a certain dimension, it is sufficient to just click the figure and then select any bar in the chart to discover the related information.
Figure 2. Linkflows and nanopublications prototype demo:
Linkflows and nanopublications prototype demo
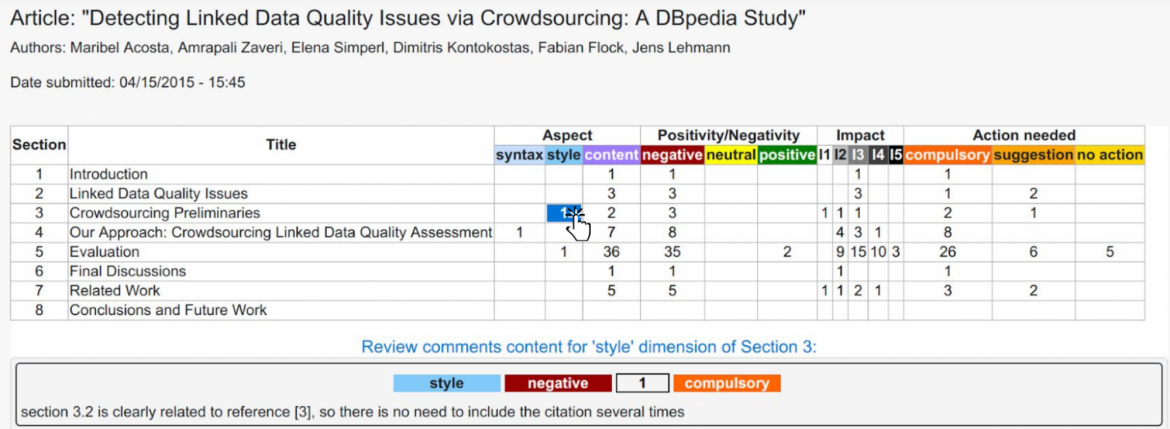
The screenshot shown in Figure 3 aggregates all the finer-grained dimensions of the review comments at the level of sections in an article. Again, in the prototype each cell in the table can be clicked, thus selecting one specific dimension of the review comments will show the comments from each reviewer underneath the table in the interface.
Figure 3. Finer-grained dimensions of review comments:
Finer-grained dimensions of review comments
We emphasize the fact that such a detailed view regarding the reviews and their content is one of the many possibilities when it comes to the graphical representation of articles and their reviews. Having all the information stored in a granular, formally-represented network allows for incredible flexibility with regard to the interpretation, visualization, and level of detail that can be shown, all in an automated manner. In a traditional publishing setting, such level of detail is not yet a possibility due to the unstructured nature of the current procedures.
What’s next: Real-case application in the publishing process
In the future, we would like to extend this fine-grained formal approach to the content of scientific articles, mainly to see if the content of the main scientific claims expressed in scientific articles could be expressed in a formal way to make scientific knowledge accessible not only to human readers, but also to automated systems. Moreover, it would be interesting to actually apply in a real-case setting, thus, in a real publishing environment, this new way of fine-grained semantic publishing for the entire scientific publishing process, from the way the publications are written, to the way they are submitted, to the peer-review process, and even the publication itself.
Background information
To find out more about our approach, you can check out the links below, including a live demo and a presentation:
“Publishing on the semantic web” by Tim Berners-Lee and James Hendler, Nature, Vol. 410, pp. 1023–1024 (2001); link: nature.com/articles/35074206 (last accessed: 25 November 2021).
“Semantic publishing: The coming revolution in scientific journal publishing” by David Shotton, Learned Publishing, Vol. 22, Iss. 2, pp. 85–94. (2009); link: onlinelibrary.wiley.com/doi/abs/10.1087/2009202 (last accessed: 25 November 2021).
“Ceci n’est pas un hamburger: Modelling and representing the scholarly article” by S. Pettifer, P. McDermott, J. Marsh, D. Thorne, A. Villeger, and T.K. Attwood, Learned Publishing, Vol. 24, Iss. 3, pp. 207–220 (2011); link: onlinelibrary.wiley.com/doi/abs/10.1087/20110309 (last accessed: 25 November 2021).
“Genuine semantic publishing” by Tobias Kuhn and Michel Dumontier, Data Science, Vol. 1, Iss. 1/2, pp. 139–154 (2017); link: content.iospress.com/articles/data-science/ds010 (last accessed: 25 November 2021).
“A Unified Nanopublication Model for Effective and User-Friendly Access to the Elements of Scientific Publishing” by Cristina-Iulia Bucur, Tobias Kuhn, and Davide Ceolin, in: Knowledge Engineering and Knowledge Management, C. Maria Keet and Michel Dumontier (Eds), EKAW 2020 Proceedings, Lecture Notes in Computer Science, Vol. 12387 (2020; Springer); link: link.springer.com/chapter/10.1007%2F978-3-030-61244-3_7 (last accessed: 25 November 2021).
“Linkflows: Enabling a web of linked semantic publishing work-flows” by Cristina-Iulia Bucur, in: The Semantic Web: ESWC 2018 Satellite Events, A.Gangemi, et al. (Eds), ESWC 2018, Lecture Notes in Computer Science, Vol. 11155 (2018; Springer); link: link.springer.com/chapter/10.1007%2F978-3-319-98192-5_45 (last accessed: 30 November 2021).
“Peer Reviewing Revisited: Assessing Research with Interlinked Semantic Comments” by Cristina-Iulia Bucur, Tobias Kuhn, and Davide Ceolin, in: K-CAP ’19: Proc. 10th Int. Conf. Knowledge Capture, M. Kejriwal, P. A. Szekely, and R. Troncy (Eds.), pp. 179–187 (2019; ACM); link: dl.acm.org/doi/proceedings/10.1145/3360901 (last accessed: 25 November 2021).
“Linkflows and nanopublications prototype demo” by Cristina-Iulia Bucur, et. al. (2020); link: linkflows.nanopubs.lod.labs.vu.nl (last accessed: 25 November 2021).
Automated decision-making affects governmental decision-making processes in terms of accountability, explainability, and democratic power. For instance, deciding on acceptable error rates reflects important value judgments that can have far-reaching ethical impacts for citizens.
Error analysis is an important determinant for the design and deployment choices in algorithms. Public authorities, therefore, need to balance the risks and benefits to protect their citizens by making error analysis transparent and understandable.