This paper was authored by Sarah Shoilee (Vrije Universiteit Amsterdam), Annastiina Ahola (Aalto University), Heikki Rantala (Aalto University), Eero Hyvönen (Aalto University), Victor de Boer (Vrije Universiteit Amsterdam), Jacco van Ossenbruggen (Vrije Universiteit Amsterdam), and Susan Legene (Vrije Universiteit Amsterdam). It reflects a fruitful collaboration between VU Amsterdam and Aalto University in Finland, made possible through Sarah’s research visit to Aalto in early 2025.
In this work, we explored how Linked Data and semantic exploration tools can be applied to support knowledge discovery in the domain of provenance research for colonial heritage collections. Using the PM-Sampo platform, we developed methods to visualize and extract provenance-related knowledge—such as the people, places, and historical events connected to cultural heritage objects—helping researchers uncover patterns that are often buried in complex archival data.
We are honored that the SemDH reviewers and community recognized the contribution of our work. We believe this award not only reflects the strength of our interdisciplinary collaboration but also the growing importance of semantic infrastructure in the Digital Humanities.
A big thank you to the SemDH organizers, reviewers, and the vibrant community around it. And heartfelt thanks to all our co-authors—it’s been a pleasure to work together!
We look forward to continuing this research and welcome new conversations and collaborations.
Workshop “Let’s talk FAIR: (Re)using FAIR vocabularies and schemas in humanities and social sciences” at DHBenelux 2025
The collaboration between projects ODISSEI and CLARIAH is producing results, for example the organization of the workshop “Let’s talk FAIR: (Re)using FAIR vocabularies and schemas in humanities and social sciences” co-located at the conference DHBenelux 2025.
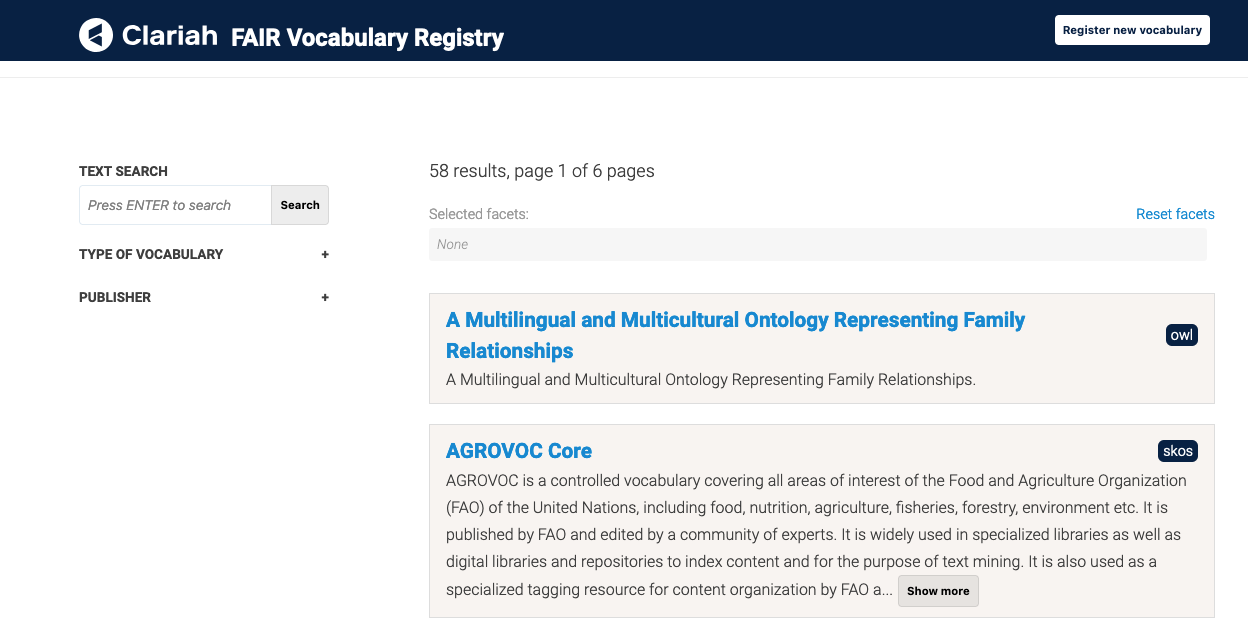
This workshop introduces the main concepts around FAIR vocabularies. “Vocabulary” is a broad concept that encompasses a wide range of knowledge representation types such as term lists, classification systems, thesauri, schemas, or ontologies (to name some of the most well-known). We will also discuss the main concepts around FAIR and FAIR assessments for vocabularies. Besides introducing the concepts, the workshop provides hands-on guidance on how to find existing vocabularies using the “SSH FAIR vocabulary registry”. It also includes practical guidelines and/or exercises for creating, publishing, (re)using vocabularies and/or assessing the FAIR-ness of vocabularies, depending on the participants interests.
More good results from this collaboration between projects ODISSEI and CLARIAH is the paper entitled “Comparing FAIR Assessment Tools and Their Alignment with FAIR Implementation Profiles Using Digital Humanities Datasets”. Accepted at semDH workshop, colocated at ESWC 2025.
As VU UCDS participants in the HEDGE-IoT project, we wrote a blog post detailing the OfficeGraph knowledge graph. You can ready it on the project website:
Authors: Sebastiaan Berendsen and Emma Beauxis-Aussalet
AI systems are vulnerable for biases that can lead to unfair and harmful outcomes. Methods to detect such biases in AI systems rely on sensitive data. However, this reliance on sensitive data is problematic due to ethical and legal concerns. Sensitive data is essential for the development and validation of bias detection methods, even when using less privacy-intrusive alternatives. Without real-world sensitive data, research on fairness and bias detection methods only concern abstract and hypothetical cases. To test their applicability in practice, it is crucial to access real-world data that includes sensitive data. Industry practitioners and policymakers are crucial actors in this process. As a society, we need legal and secure ways to use real-world sensitive data for bias detection research.
In this blog, we discuss what bias detection and sensitive data are, and why sensitive data is required. We also outline alternative approaches that would be less privacy-intrusive. We conclude with ways forward that all require collaboration between researchers and industry practitioners.
What is bias detection?
AI fairness is about enabling AI systems that are free of biases. A key approach to analyze AI fairness is bias detection. Bias detection attempts to identify structural differences in the results of an AI system for different groups of people. Most methods to detect bias use sensitive data. Sensitive data describes the characteristics of specific socio-demographic groups1. These characteristics can be inherent (e.g., gender, ethnicity, age) or acquired (e.g., religion, political orientation), and are often protected by anti-discrimination laws and privacy regulations. If sensitive information is not used in an AI system, its outcomes can still be biased. We therefore need to explore how we can use sensitive data legally and ethically for bias detection.
In practice, sensitive data is often completely unavailable or of poor quality due to privacy, legal, and ethical concerns. The lack of access to high-quality sensitive data hinders the implementation of bias detection methods in practice.
Concerns regarding the use of sensitive data
The use of certain sensitive data for bias detection might be prohibited by the GDPR2. However, the EU AI Act provides an exception to the GDPR that allows the use of special category data for bias detection purposes. Such usage of sensitive data is subjected to appropriate safeguards. Yet, the definition of appropriate safeguards remains unclear and the exception is strictly limited to the high-risk models defined by the EU AI Act.
Even if the EU AI Act might address some legal concerns, key ethical concerns remain3,4. Widespread collection of sensitive data increases the risks of data misuse and abuse, such as citizen surveillance. Furthermore, obtaining accurate, representative sensitive data is a challenge. Inaccurate sensitive data harms the validity of bias detection methods and heightens the risk of misclassifying and misrepresenting individuals and their social groups.
Alternative approaches
Two approaches5 seem most promising to enable bias detection w.r.t. sensitive data: the trusted third party approach and the analytical approach. The trusted third party approach consists of letting a neutral party hold sensitive data, and run bias analyses on their premises. Such third parties do not share any sensitive data, but only the results of the bias analysis. These trusted third parties can be governmental organizations, such as national statistics or census bureaus, or non-governmental organizations.
The analytical approach consists of data analysis methods that do not require direct access to sensitive data. For example, such methods can be based on proxy variables, unsupervised learning models, causal fairness methods, or synthetic data generated with privacy-preserving technologies. Some of these methods could still require some sensitive data, but they remain less privacy-intrusive than other methods.
These alternative approaches do not structurally remove the need to use sensitive data. Besides, these approaches are currently understudied, and more research is needed to develop and validate them. This research requires controlled access to sensitive data, until such privacy-preserving bias detection approaches are properly validated, and their strengths and weaknesses are well-defined and measurable.
Ways forward
The lack of access to realistic data from real-world AI systems is a crucial challenge. The literature on AI fairness mostly relies on datasets with limited practical context1. Therefore, existing bias detection methods are primarily tested “in-the-lab”. Insights into the validity of the bias detection methods in real-world applications are lacking. Yet, such insights are essential to justify the needs for collecting sensitive data to address AI bias in practice. This is required to understand whether the methods to address AI fairness are effective or not in the socio-technical context of AI systems.
Researchers cannot fix this challenge on their own. Collaboration between researchers, (non) governmental organizations, and industry practitioners is essential to address the challenges with fairness methods, and to increase their practicality and validity. A research collaboration is also needed to address the legal and ethical concerns, and specify the necessary safeguards. For example, the GDPR and EU AI Act contains exceptions for sensitive data processing for scientific purposes, when it adheres to recognised ethical standards for scientific research.
Closing
Sensitive data is essential for investigating the technical approaches to ensure AI fairness. However, the availability of accurate sensitive data remains a challenge. Alternative approaches exist to preserve privacy while using sensitive data for bias analysis. Yet these approaches are currently understudied, and more research is needed. For such research to be effective, collaboration is needed between researchers and practitioners from industry or public institutions.
The world of semantic technologies and knowledge graphs came alive at SEMANTiCS 2023, held September 20-22, 2023, at the HYPERION Hotel in Leipzig, Germany. As an attendee of this vibrant conference, I was eager to explore the latest developments in the field and engage with experts from various domains. This year, SEMANTiCS centred around the theme “Knowledge Graphs in the era of Large Language Models (LLM)”. With a captivating program, enlightening talks, and an array of valuable discussions, SEMANTiCS 2023 was an enriching experience.
The Program and Proceedings
The SEMANTiCS 2023 program was a testament to the conference’s commitment to staying at the forefront of semantic technologies. The proceedings are available here.
The theme, “Knowledge Graphs in the era of Large Language Models (LLM)”, underscores the evolving landscape of knowledge representation. LLMs, such as GPT-3, have revolutionised(or evolutionised?) natural language generation and understanding. Therefore, the necessity of a shift towards hybrid AI, where rule-based systems collaborate with LLMs, was a recurring topic. The blending of structured data with LLMs opens up new avenues for Natural Language Interpretation (NLI).
Keynote Highlights
The keynote sessions were a highlight of SEMANTiCS 2023. They provided deep insights into the challenges and opportunities in the world of knowledge graphs and large language models. Here are some key takeaways from the keynote sessions:
Edward Curry, in his DBpedia keynote, emphasised the importance of handling messy, heterogeneous data in the era of knowledge graphs. He presented principles for creating robust data space systems.
Xin Luna Dong, during her keynote, delved into the history of knowledge graphs and highlighted the challenges faced in knowledge extraction and fusion. She shed light on how knowledge graphs are integral to covering long-tail problems.
Aidan Hogan explored the synergy between Large Language Models and Knowledge Graphs, presenting an optimistic vision for the future. His session introduced various cutting-edge works in the field, providing valuable resources for further exploration.
Stephen Gilbert discussed governance and evidence frameworks for chatbots in medicine, highlighting the role of technologies in shaping human behaviour and decision-making.
Marco Varone shared his 30-year journey in the world of language understanding, emphasising the continued need for symbolic AI in Natural Language Understanding and Generation, complementing Large Language Models.
My Conference Talk
The two talk I attended as a presenter are following:
DBpedia: The DBpedia sessions focused on topics related to DBpedia, unified metadata, and principles of data space systems. DBpedia members took the stage to showcase their latest tools, applications, and technical developments. Being a member of DBpedia, the Network Institute(NI) at Vrije Universiteit(VU) Amsterdam shared insights how DBpedia can be a potential source of open data for the works done in collaboration with Cultural AI Lab. As a representative of Network Institute, I gave a presentation on illustrating NI’s collaboration with Cultural AI lab and research highlights from the lab. The presentation slides are here.
Research Talks on Cultural Heritage: This panel explored knowledge graph-based representations of historical cities, virtual reality access to knowledge graphs, and the Dutch Linked Data Space for cultural heritage. I presented the findings from my accepted paper @ SEMNATiCS 2023: Polyvocal Knowledge Modelling for Ethnographic Heritage Object Provenance. This work addresses the challenge of representing the provenance of ethnographic objects. By adapting a combined model that can express the heterogeneity and polyvocality of object provenance information, the work fosters contextualization, findability, and reusability of this knowledge. Presentation slides are here.
Therefore, we (authors of the paper) received a hand-drawing illustration of the research talk. 😉
Closing Thoughts
SEMANTiCS 2023 was a valuable experience that provided insights into the dynamic and evolving world of knowledge graphs and large language models. The theme of bridging rule-based systems with LLMs, the prominence of data spaces, and the focus on scientific publishing were central themes. Notable papers, cutting-edge technologies, and inspiring keynotes made the conference a must-attend event for anyone interested in semantic technologies. While I may not have won an award, the knowledge and connections gained at the conference were certainly a reward in themselves.
The award for the Best Network Institute Academy Assistant project for this year goes to the project titled “Between Art, Data, and Meaning – How can Virtual Reality expand visitors’ perspectives on cultural objects with colonial background?” This project was carried out by VU students Isabel Franke and Stefania Conte, supervised by Thilo Hartmann and UCDS researchers Claudia Libbi and Victor de Boer. A project report and research paper is forthcoming but you can see the poster below.
It has pleased NWO to award the HAICu consortium funding under the National Research Agenda programme. In the HAICu project, AI researchers, Digital Humanities researchers, heritage professionals and engaged citizens work together on scientific breakthroughs to open, link and analyze large-scale multimodal digital heritage collections in context.
At VU, researchers from the User-Centric Data Science group will research how to create compelling narratives as a way to present multiple perspectives in multimodal data and how to provide transparency regarding the origin of data and the ways in which it was created. These questions will be addressed in collaboration with the Museum for World Cultures on how citizen-contributed descriptions can be combined with AI-generated labels into polyvocal narratives around objects related to the Dutch colonial past in Indonesia.