
This blog post is written by Cristina-Iulia Bucur, and cross-posted at the IOS Press Labs website

We currently disseminate, share, and evaluate scientific findings following paradigms of publishing where the only difference from the methods of more than 300 years ago is the medium in which we publish – we have moved from printed articles to digital format, but still use almost the same natural language narrative with long coarse-grained text with complicated structures. These are optimized for human readers and not for automated means of organization and access. Additionally, peer reviewing is the main method of quality assessment, but these peer reviews are rarely published and have their own complicated structure, with no accessible links to the respective articles. With the increasing number of articles being published, it is difficult for researchers to stay up to date in their specific fields, unless we find a way to involve machines as well in this whole process. So, how can we make use of the current technologies to change these old paradigms of publishing and make the process more transparent and machine-interpretable?
In order to address these problems and to better align scientific publishing with the principles of the Web and linked data, my research proposes an approach to use nanopublications – in the form of a fine-grained unifying model – to represent in a semantic way the elements of publications, their assessments, as well as the involved processes, actors, and provenance in general. This research is a result of the collaboration between Vrije Universiteit Amsterdam, IOS Press, and the Netherlands Institute for Sound and Vision for the Linkflows project. The purpose of this project is to make scientific contributions on the Web, e.g. articles, reviews, blog posts, multimedia objects, datasets, individual data entries, annotations, discussions, etc., better valorized and efficiently assessed in a way that allows for their automated interlinking, quality evaluation, and inclusion in scientific workflows. My involvement in the Linkflows project is in collaboration with Tobias Kuhn, Davide Ceolin, Jacco van Ossenbruggen, Stephanie Delbecque, Maarten Fröhlich, and Johan Oomen.
Semantic publishing
One concept that first comes to mind and a proposed solution to make scientific publishing machine-interpretable is “semantic publishing.” This is not a new concept, as its roots are tightly coupled to the notion of the Web, with Tim Berners-Lee mentioning that the semantic web “will likely profoundly change the very nature of how scientific knowledge is produced and shared, in ways that we can now barely imagine” [1]. Despite the fact that semantic publishing is not directly linked to the Web, its progress was highly influenced by the rise of the “semantic web.” As such, in the beginning, it referred to mainly publishing information on the Web in the form of documents that additionally contain structured annotations, so extra information that is parsable by machines in the form of semantic markup (with markup languages like RDFa, for example). This allowed published information on the Web to be machine-interpretable, to the limited extent to which the markup languages allowed. A next step was to use semantic web languages like RDF and OWL to publish information in the form of data objects, together with a specific detailed representation called ontology that is able to represent the domain of the data in a formal (thus machine-interpretable) way. The information published in such structured ways provides not only a “semantic” context through the metadata that describes the information, but also a way for machines to understand the structure and even the meaning of the published information [2,3].
In this way, semantic publishing would allow for the “automated discovery, enables its linking to semantically related articles, provides access to data within the article in actionable form, or facilitates integration of data between papers” [3]. However, despite all the advancements in the semantic web technologies in the past years, semantic publishing is not “genuine” [4] in the sense that the current scientific publishing paradigm has not changed much as we are still using long articles written in natural language that do not contain formal semantics from the start that machines can process and interpret in an automated manner. So, with scientific publishing often stuck to formats optimized for print such as PDF, we are not using the advances that are available to us with technologies around the semantic web and linked data.

Transforming scholarly articles into small, interlinked snippets of data
In our approach, we argue for a new system of scientific publishing that contains smaller, fine-grained, formal – machine-interpretable – representations of scientific knowledge that are linked together in a big knowledge network in a web-like fashion in a way that these publications do not need to be necessarily linked to a journal or a traditional publication and can be publication entities by themselves [5,6]. Moreover, semantic technologies make possible the decomposition of traditional science articles into constituent machine-readable parts that are linked not only with one another, but also to other related fine-grained parts of knowledge on the Web following the linked data principles. So, we designed a model for a more granular and semantic publishing paradigm, which can be used for scientific articles as well as reviews.
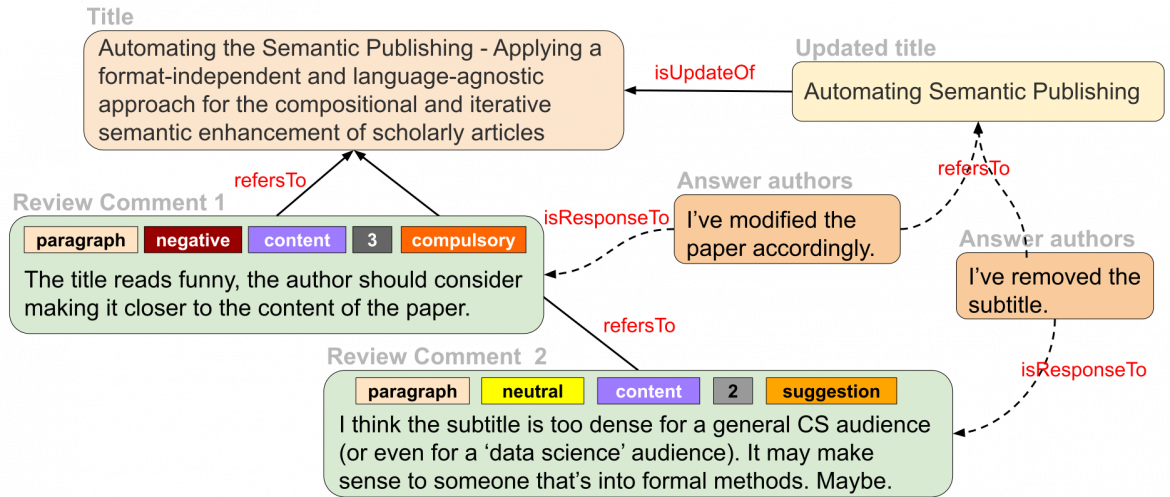
The scientific publishing process at a granular level
An example based on this is shown in Figure 1. Here, we see how the scientific publishing process can look at a more finely-grained level, with a network-like representation and with the recording of formal semantics for the different elements. Instead of treating big bulks of text as such, we propose to represent them as small snippets – such as paragraphs, or a title in this example – that have formal semantics attached and can be treated as independent publication units. They can link to other such units and therefore form a larger entity – such as a full paper or review – by forming a complex network of links. With that approach, we can ensure that provenance of each snippet of information can be accurately tracked together with its creation time and author, and therefore allow for more flexible and more efficient publishing than the current paradigm.
Reimagining the peer-review process
A process like peer reviewing can then be broken down into small snippets and thereby take the specialization of reviewers and the detailed context of their review comments into account, and these review comments can formally and precisely link to exactly the parts of the paper they address. These small snippets of text can be represented as nodes in a network and can be linked with one another with semantically-annotated connections, thus forming distributed and semantically annotated networks of contributions.
The individual review comments are semantically modeled with respect to the specific part of the paper that they target – whether they are about syntax or content, whether they raise a positive or negative point, and whether they are a suggestion or compulsory, and what their impact on the quality of the paper is, according to our previous proposed model [7]. Each article, paragraph, and review comment thereby forms a single node in a network and is each identified by a dereferenceable URI (uniform resource identifier). All this is very different to how scientific communication happens nowadays, with the long non-machine interpretable natural-language coarse-grained texts, thus large non-semantic documents.
Practical applications for journal editors
This formal networked approach allows us, among other things, to provide general, user-friendly, and powerful aggregations, for example for journal editors, that can assist them in their meta-reviewing tasks. Shown in Figure 2 are two screenshots from a prototype system [8]. We can see in a more quantitative way the set of review comments and their types represented in different colors, where the checkboxes in the legend can be used to filter the review comments of the given category. To see the content of the review comments that are in a certain dimension, it is sufficient to just click the figure and then select any bar in the chart to discover the related information.
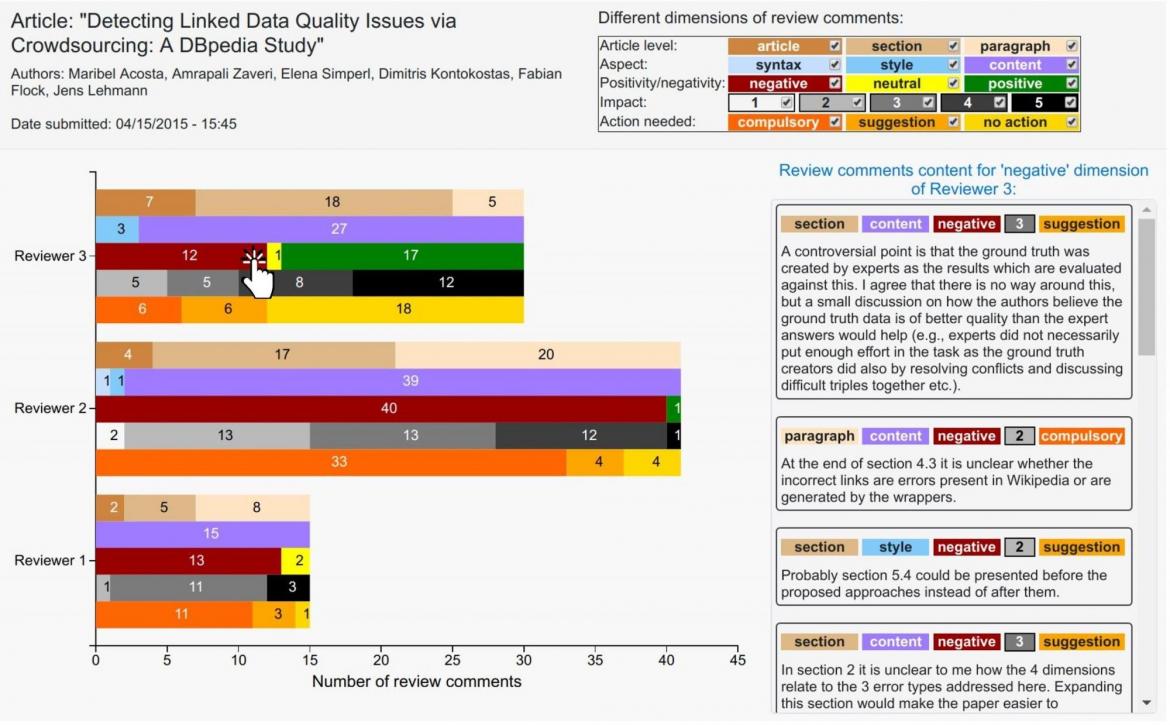
Linkflows and nanopublications prototype demo
The screenshot shown in Figure 3 aggregates all the finer-grained dimensions of the review comments at the level of sections in an article. Again, in the prototype each cell in the table can be clicked, thus selecting one specific dimension of the review comments will show the comments from each reviewer underneath the table in the interface.
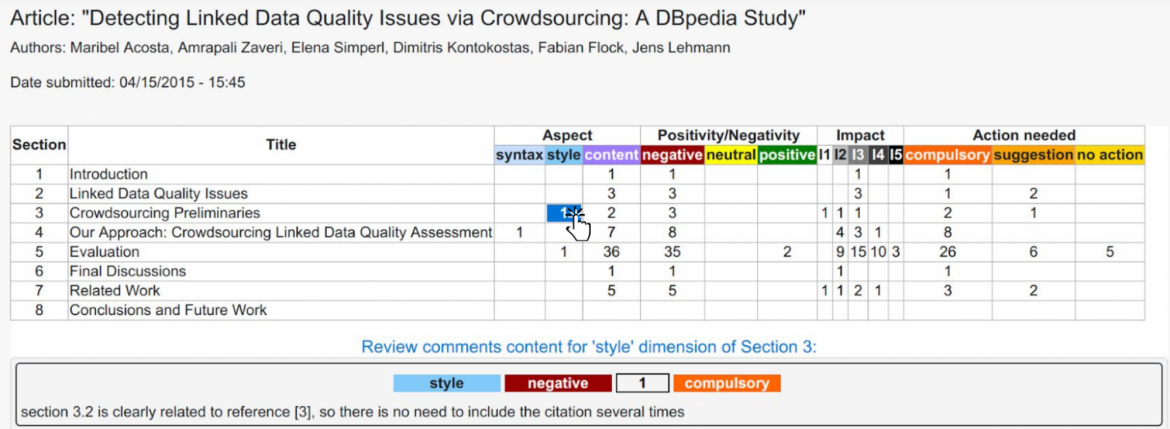
Finer-grained dimensions of review comments
We emphasize the fact that such a detailed view regarding the reviews and their content is one of the many possibilities when it comes to the graphical representation of articles and their reviews. Having all the information stored in a granular, formally-represented network allows for incredible flexibility with regard to the interpretation, visualization, and level of detail that can be shown, all in an automated manner. In a traditional publishing setting, such level of detail is not yet a possibility due to the unstructured nature of the current procedures.
What’s next: Real-case application in the publishing process
In the future, we would like to extend this fine-grained formal approach to the content of scientific articles, mainly to see if the content of the main scientific claims expressed in scientific articles could be expressed in a formal way to make scientific knowledge accessible not only to human readers, but also to automated systems. Moreover, it would be interesting to actually apply in a real-case setting, thus, in a real publishing environment, this new way of fine-grained semantic publishing for the entire scientific publishing process, from the way the publications are written, to the way they are submitted, to the peer-review process, and even the publication itself.
Background information
To find out more about our approach, you can check out the links below, including a live demo and a presentation:
- Article: “A Unified Nanopublication Model for Effective and User-Friendly Access to the Elements of Scientific Publishing” [5]
- Demo: Linkflows and nanopublications prototype [8]
- Video: Presentation from the 22nd International Conference on Knowledge Engineering and Knowledge Management (EKAW20, September 2020)
- Slides: EKAW20 conference presentation
References
- “Publishing on the semantic web” by Tim Berners-Lee and James Hendler, Nature, Vol. 410, pp. 1023–1024 (2001); link: nature.com/articles/35074206 (last accessed: 25 November 2021).
- “Semantic publishing: The coming revolution in scientific journal publishing” by David Shotton, Learned Publishing, Vol. 22, Iss. 2, pp. 85–94. (2009); link: onlinelibrary.wiley.com/doi/abs/10.1087/2009202 (last accessed: 25 November 2021).
- “Ceci n’est pas un hamburger: Modelling and representing the scholarly article” by S. Pettifer, P. McDermott, J. Marsh, D. Thorne, A. Villeger, and T.K. Attwood, Learned Publishing, Vol. 24, Iss. 3, pp. 207–220 (2011); link: onlinelibrary.wiley.com/doi/abs/10.1087/20110309 (last accessed: 25 November 2021).
- “Genuine semantic publishing” by Tobias Kuhn and Michel Dumontier, Data Science, Vol. 1, Iss. 1/2, pp. 139–154 (2017); link: content.iospress.com/articles/data-science/ds010 (last accessed: 25 November 2021).
- “A Unified Nanopublication Model for Effective and User-Friendly Access to the Elements of Scientific Publishing” by Cristina-Iulia Bucur, Tobias Kuhn, and Davide Ceolin, in: Knowledge Engineering and Knowledge Management, C. Maria Keet and Michel Dumontier (Eds), EKAW 2020 Proceedings, Lecture Notes in Computer Science, Vol. 12387 (2020; Springer); link: link.springer.com/chapter/10.1007%2F978-3-030-61244-3_7 (last accessed: 25 November 2021).
- “Linkflows: Enabling a web of linked semantic publishing work-flows” by Cristina-Iulia Bucur, in: The Semantic Web: ESWC 2018 Satellite Events, A.Gangemi, et al. (Eds), ESWC 2018, Lecture Notes in Computer Science, Vol. 11155 (2018; Springer); link: link.springer.com/chapter/10.1007%2F978-3-319-98192-5_45 (last accessed: 30 November 2021).
- “Peer Reviewing Revisited: Assessing Research with Interlinked Semantic Comments” by Cristina-Iulia Bucur, Tobias Kuhn, and Davide Ceolin, in: K-CAP ’19: Proc. 10th Int. Conf. Knowledge Capture, M. Kejriwal, P. A. Szekely, and R. Troncy (Eds.), pp. 179–187 (2019; ACM); link: dl.acm.org/doi/proceedings/10.1145/3360901 (last accessed: 25 November 2021).
- “Linkflows and nanopublications prototype demo” by Cristina-Iulia Bucur, et. al. (2020); link: linkflows.nanopubs.lod.labs.vu.nl (last accessed: 25 November 2021).
Leave a Reply